
AI Technical Audit — Can LLMs Actually Read Your Website?
Most brands investing in GEO start with content. They write authoritative articles, add schema markup, and wait to appear in ChatGPT or Perplexity responses. Nothing happens.
The reason is almost always technical. Before a language model can cite your brand, three things have to be true: it has to be allowed onto your page, it has to find readable content when it gets there, and it has to understand what that content means. CiteVista's AI Technical Audit checks all three — in that exact order.
In our own testing across dozens of sites using CiteVista, the pattern is consistent: most brands fail not because their content is weak, but because AI crawlers never reach it, can't parse it, or have no structured signal to identify what the brand actually is.
The Audit Funnel: Three Questions, Three Modules
Most technical audits treat every check as equal. CiteVista's AI Technical Audit is structured as a funnel because AI readability problems follow a specific sequence. A failure at any layer makes the layers below irrelevant.
Module 1 — Can AI crawlers get in? Before anything else, your robots.txt, HTTP status, and indexing directives determine whether AI bots are even allowed to visit your page. If GPTBot is blocked, no amount of schema or content quality will help.
Module 2 — What do they see when they arrive? Once a crawler gets in, your HTML structure determines whether it can understand what your page is about. Heading hierarchy, language tags, and Open Graph data tell AI models how to interpret and categorize your content.
Module 3 — Can they actually read and trust it? This is where most sites fail silently. JavaScript-dependent content is invisible to AI crawlers. Missing schema means models have to guess what your brand is. Without sameAs fields, there is no entity verification across platforms.
Each module builds on the previous one. Running them in sequence gives you a complete picture of where the breakdown is happening.
Module 1 — Basic Indexing Check
The question it answers: Are AI crawlers technically allowed to access this page?
This is the foundation. A site can have perfect content and flawless schema — but if robots.txt blocks GPTBot or the page returns a non-200 status code, the content is invisible to every AI platform that relies on that crawler.
When we ran CiteVista's Basic Indexing Check across a range of sites, bot access issues were one of the most frequently flagged problems. Many sites had no robots.txt file at all — which means AI crawlers are operating without explicit permission signals. Others had CDN-level configurations that silently overrode their robots.txt rules, blocking GPTBot or ClaudeBot without the site owner realizing it. A general Allow: * rule does not guarantee that specific AI crawlers are permitted — and the audit surfaces exactly which bots are blocked, and why.
The Basic Indexing Check runs 13 technical signals across 5 categories using lightweight HTTP requests — no JavaScript rendering, results in 2–4 seconds.
What it checks:
- Access Control — robots.txt availability, URL-level blocking rules, per-bot AI crawler permissions (GPTBot, ClaudeBot, PerplexityBot, Google-Extended, CCBot, Bytespider)
- Indexing Directives — noindex/nofollow meta tags, X-Robots-Tag headers
- HTTP Response — status codes (200/301/404), redirect chain cleanliness
- Canonical Setup — canonical tag presence, self-canonical validation
- Discoverability — sitemap existence, parseability, whether the target URL is included
What the report shows:
Results appear as a 0–100 score with a status label (Healthy / Needs Improvement / Critical), colored access badges for each AI crawler, and a detailed pass/warning/failed breakdown for every check. Failed items represent active blockers — direct impact on AI visibility with zero score weight.
 Basic Indexing Check input screen
Target URL input and audit configuration screen for the Basic Indexing Check module.
Basic Indexing Check input screen
Target URL input and audit configuration screen for the Basic Indexing Check module.
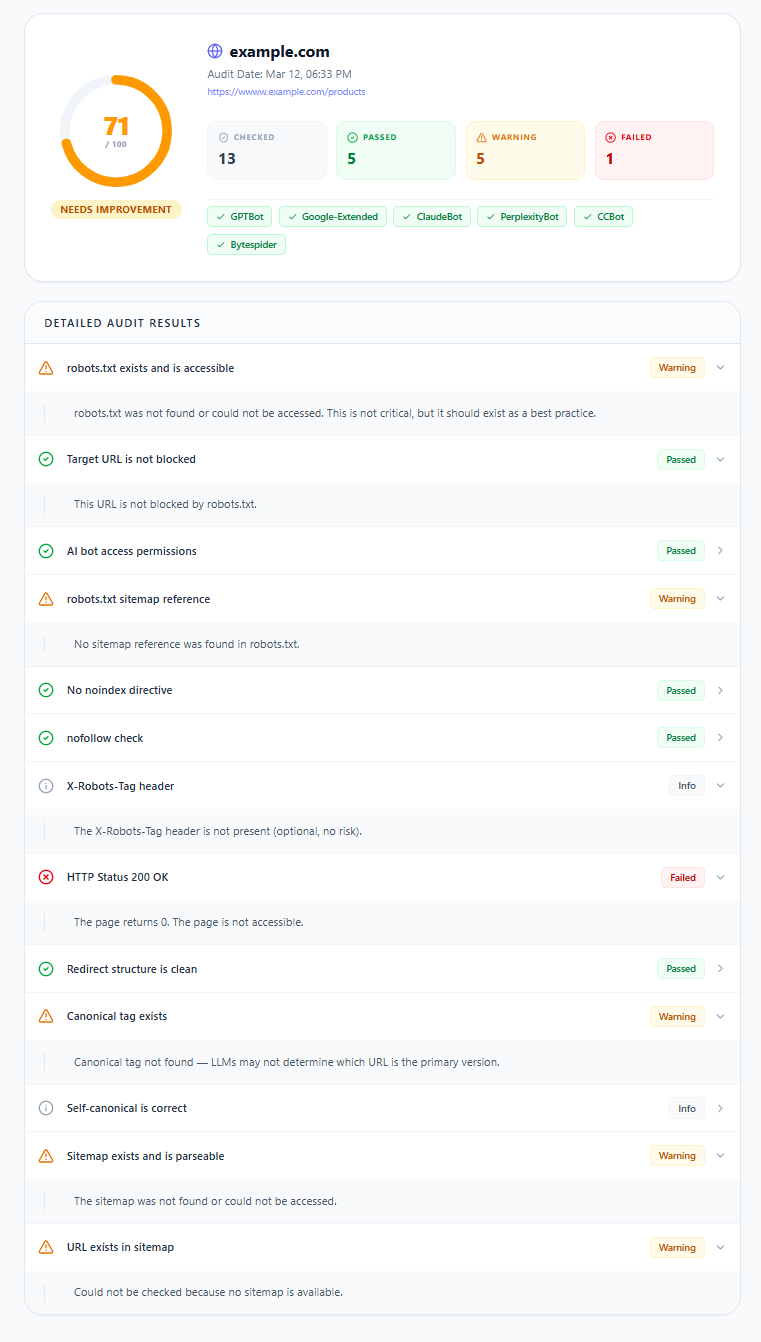 Basic Indexing Check report output
Audit report showing overall readiness score, AI crawler access status, and detailed check results across all five categories.
Basic Indexing Check report output
Audit report showing overall readiness score, AI crawler access status, and detailed check results across all five categories.
Module 2 — Content Structure Scan
The question it answers: When an AI crawler arrives, can it understand what your page is about?
Getting past the access layer is only the beginning. Once a crawler is on your page, it needs to extract meaning from your HTML. If your heading hierarchy is broken, your language tags are missing, or your Open Graph data doesn't match your canonical URL, AI models will either misclassify your content or skip it entirely.
In CiteVista's testing, heading structure issues appeared consistently across sites that otherwise looked well-optimized. The most common pattern: an H1 exists but H2 headings are skipped entirely, with content jumping directly to H3. This breaks the logical document hierarchy that LLMs use to understand topic relationships on a page. Another frequent finding was title tags exceeding 70 characters — a signal that's problematic for both traditional search indexing and AI snippet generation, where truncated titles reduce the clarity of what the page is about.
The Content Structure Scan runs 12 technical signals across 4 categories — also without JavaScript rendering, results in 3–5 seconds.
What it checks:
- Title & H1 — title tag presence and length (70 character threshold), H1 existence, single H1 usage, meaningful heading content
- Heading Hierarchy — H2/H3 nesting consistency, level-skipping detection, section separation clarity
- Language Signals — html lang attribute validity, hreflang tags for multi-regional sites, format correctness
- Open Graph & Meta — og:title and og:description presence, og:url and canonical URL consistency
What the report shows:
Same 0–100 scoring system with status labels. The most impactful checks are Title, H1, H2/H3 hierarchy, html lang, and og:title/og:description. A failed hreflang on a multi-regional site is one of the most common and most overlooked reasons brands appear inconsistently across different language markets in AI-generated responses.
 Content Structure Scan input screen
Target URL input and audit configuration screen for the Content Structure Scan module.
Content Structure Scan input screen
Target URL input and audit configuration screen for the Content Structure Scan module.
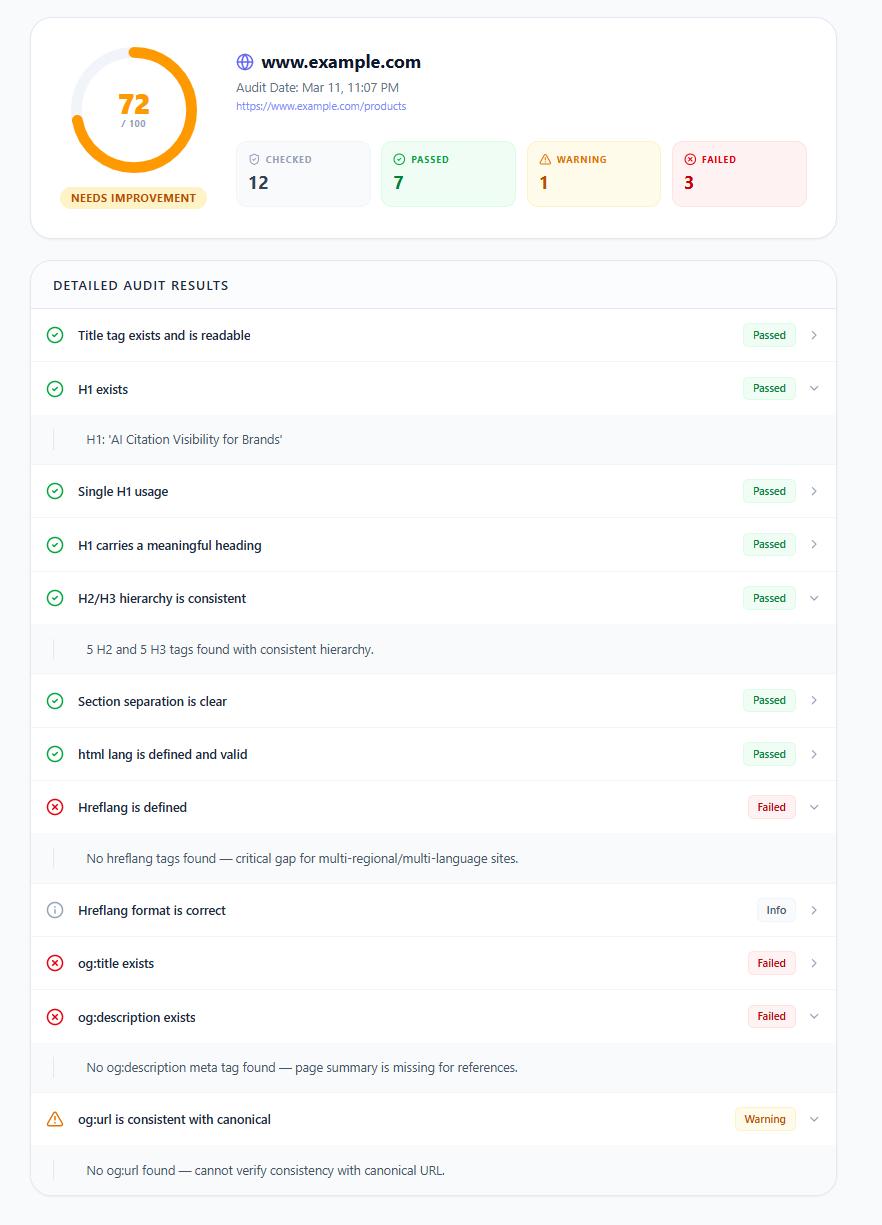 Content Structure Scan report output
Audit report showing content structure score, heading hierarchy analysis, and pass/warning/failed status across all structural checks.
Content Structure Scan report output
Audit report showing content structure score, heading hierarchy analysis, and pass/warning/failed status across all structural checks.
Module 3 — Deep AI Crawl & Schema
The question it answers: Can AI models actually read your content — and do they know who you are?
This is the deepest layer of the audit and carries the most weight in CiteVista's scoring formula (50% of the Full Technical Audit overall score). It addresses the two most common reasons well-optimized brands don't appear in AI-generated answers: their content is hidden behind JavaScript, and their entity identity isn't verifiable.
The Deep AI Crawl & Schema module fetches your page twice — once as raw HTML (what a basic crawler sees) and once with JavaScript fully executed (what a browser renders). The difference between these two reveals exactly how much of your content depends on client-side rendering.
When we audited sites using CiteVista, high JavaScript dependency was the single most widespread technical barrier to AI visibility. Sites built on modern JS frameworks without server-side rendering consistently showed render differences above 50% — meaning AI crawlers were seeing less than half the content visible to a human visitor. In some cases, the raw HTML returned nearly nothing: a loader shell with no meaningful text.
Beyond JS rendering, schema markup was absent or severely limited on the majority of sites we tested. When schema did exist, sameAs fields were almost never present — which means even if a model finds the content, it has no way to verify the brand entity across external platforms like LinkedIn, Wikidata, or Crunchbase. This cross-platform entity verification is how LLMs build confidence in citing a brand consistently.
What it checks:
- JS Rendering & Content — dual-pass render comparison, raw HTML content presence, empty shell detection, main content block identification, content-to-boilerplate ratio
- Access Barriers — cookie wall detection, login wall detection, interstitial popup detection
- Schema & Entity — JSON-LD/Microdata existence and parseability, schema type relevance for page content, sameAs field validation
- AI Bot Access — per-bot permission analysis for all 6 major AI crawlers
The JS dependency percentage is the single most important number in this audit. It measures the gap between raw HTML character count and fully rendered character count:
- 0–15% — Ideal. Content loads without JavaScript.
- 15–50% — Warning. Significant content is behind JS rendering.
- 50%+ — Critical. Most AI crawlers see a near-empty page.
Schema markup carries the second-highest weight. Without JSON-LD structured data, language models have no explicit signal about what your brand is, what category it belongs to, or how to verify your entity. The sameAs validation check specifically looks for whether your schema connects your brand to external sources — because these cross-platform signals are how LLMs confirm entity identity before including a brand in generated responses.
What the report shows:
A summary panel showing JS Dependency percentage with a visual bar, content/boilerplate ratio, and AI crawler access badges. Below, the full detailed check list with pass/warning/failed/error status for each signal.
 Deep AI Crawl & Schema input screen
Target URL input and audit configuration screen for the Deep AI Crawl & Schema module.
Deep AI Crawl & Schema input screen
Target URL input and audit configuration screen for the Deep AI Crawl & Schema module.
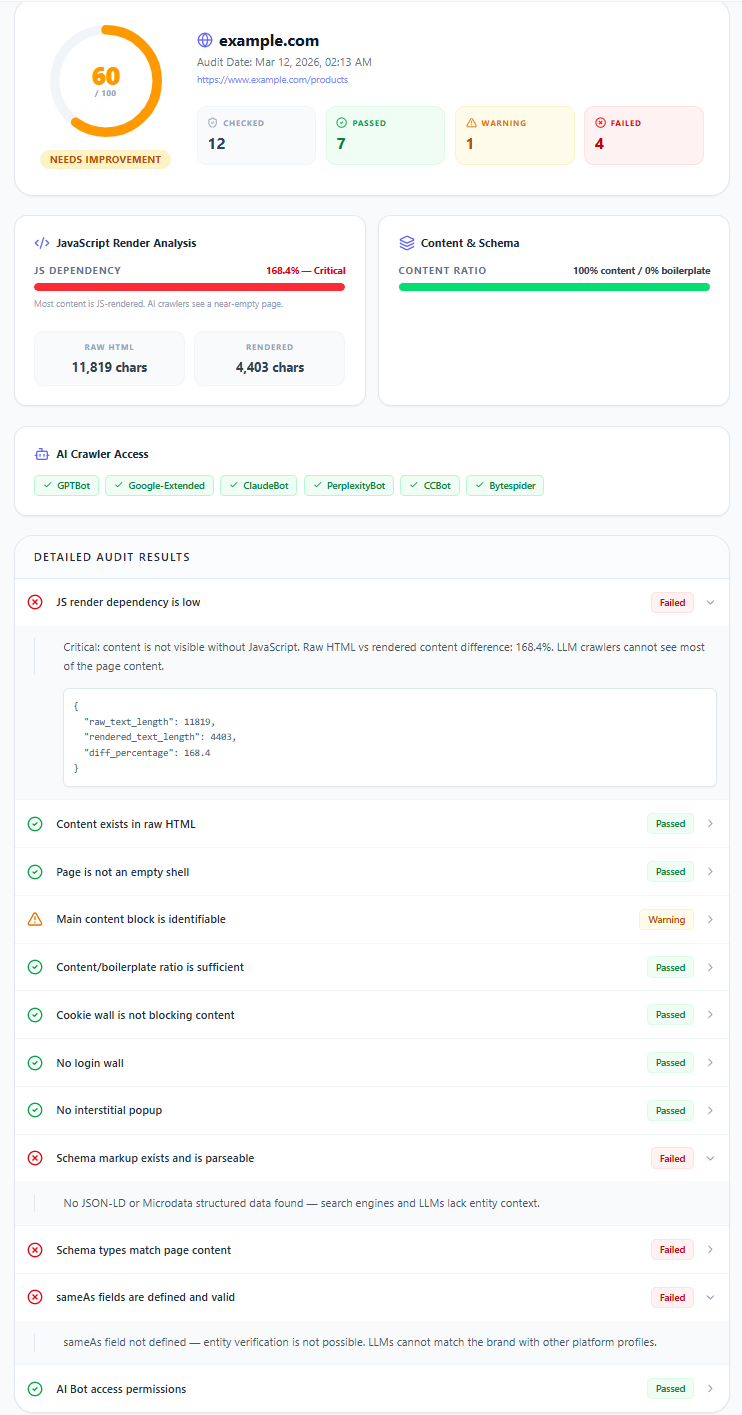 Deep AI Crawl & Schema report output
Audit report showing JavaScript render dependency analysis, content/boilerplate ratio, schema markup evaluation, and per-bot crawler access status.
Deep AI Crawl & Schema report output
Audit report showing JavaScript render dependency analysis, content/boilerplate ratio, schema markup evaluation, and per-bot crawler access status.
Full Technical Audit — All Three Modules in One Report
For a complete picture of your page's AI readiness, CiteVista's Full Technical Audit runs all three modules in a single pass — 37 signals across every dimension that affects whether AI models can access, understand, and cite your content.
The overall score combines all three modules using a weighted formula:
Overall = Module 1 × 0.25 + Module 2 × 0.25 + Module 3 × 0.50
Module 3 carries 50% of the weight because JS rendering, schema markup, and bot permissions are the strongest predictors of whether AI models can actually read and cite your content. Modules 1 and 2 are foundational hygiene — they need to pass, but passing them alone does not guarantee AI visibility.
The report identifies your Top Critical Issues automatically — the highest-weight failed checks across all three modules, sorted by impact. This means you always know exactly where to focus first, without having to interpret 37 individual check results yourself.
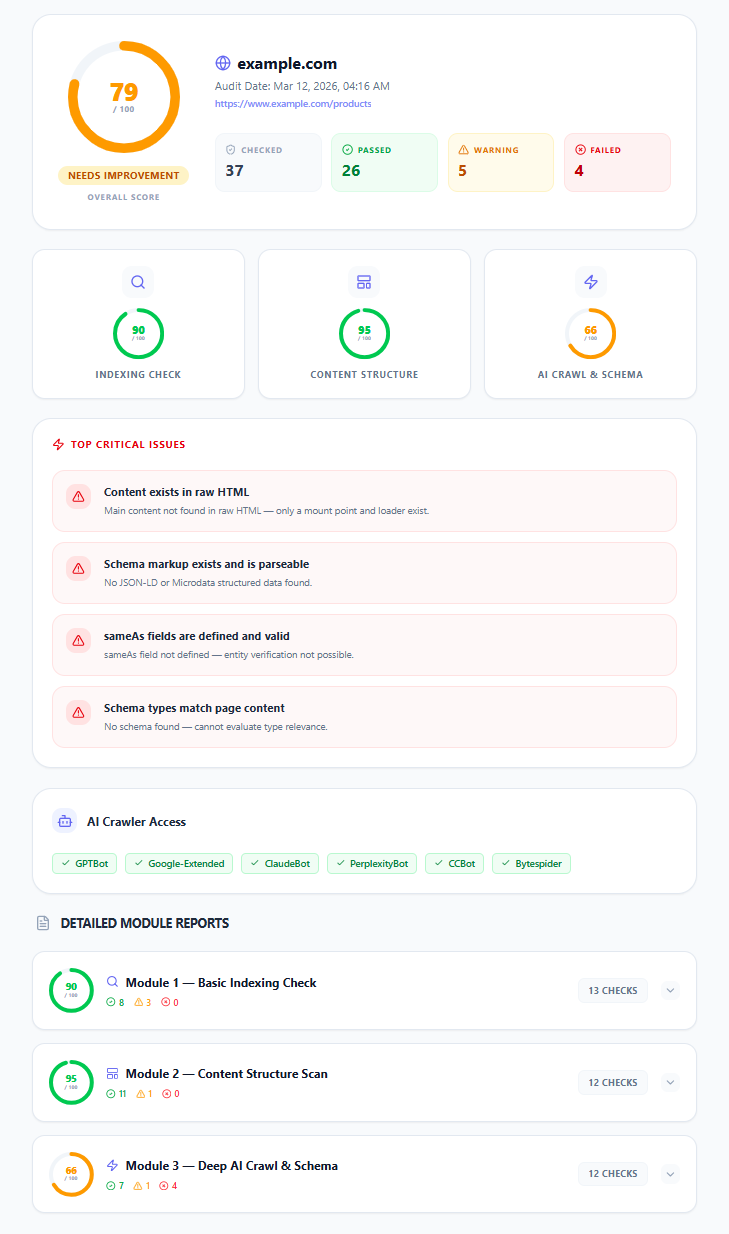 Full Technical Audit overall score
Full Technical Audit overview — overall AI readiness score, individual module score cards, top critical issues, and AI crawler access summary.
Full Technical Audit overall score
Full Technical Audit overview — overall AI readiness score, individual module score cards, top critical issues, and AI crawler access summary.
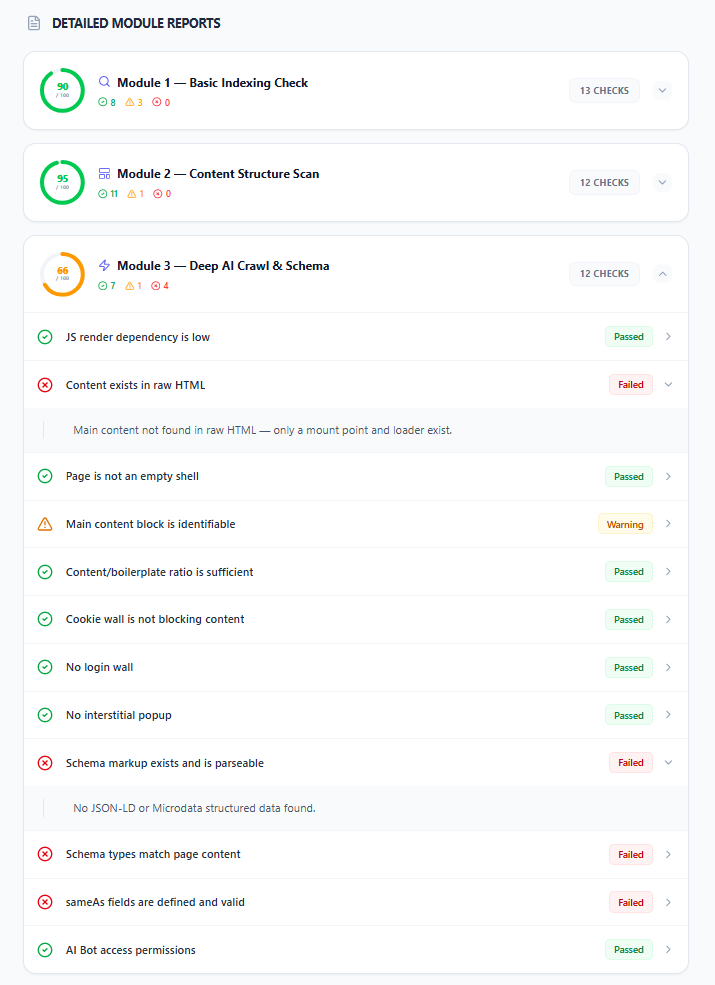 Full Technical Audit module breakdown
Detailed module reports showing individual check results across all three audit modules in a single consolidated view.
Full Technical Audit module breakdown
Detailed module reports showing individual check results across all three audit modules in a single consolidated view.